Speech Emotion Recognition System for Human-Machine Interaction on Edge–Cloud System
Keywords:
Speech Emotion Recognition, Convolutional Neural Networks, Feature Extraction, IoT Embedded SystemsAbstract
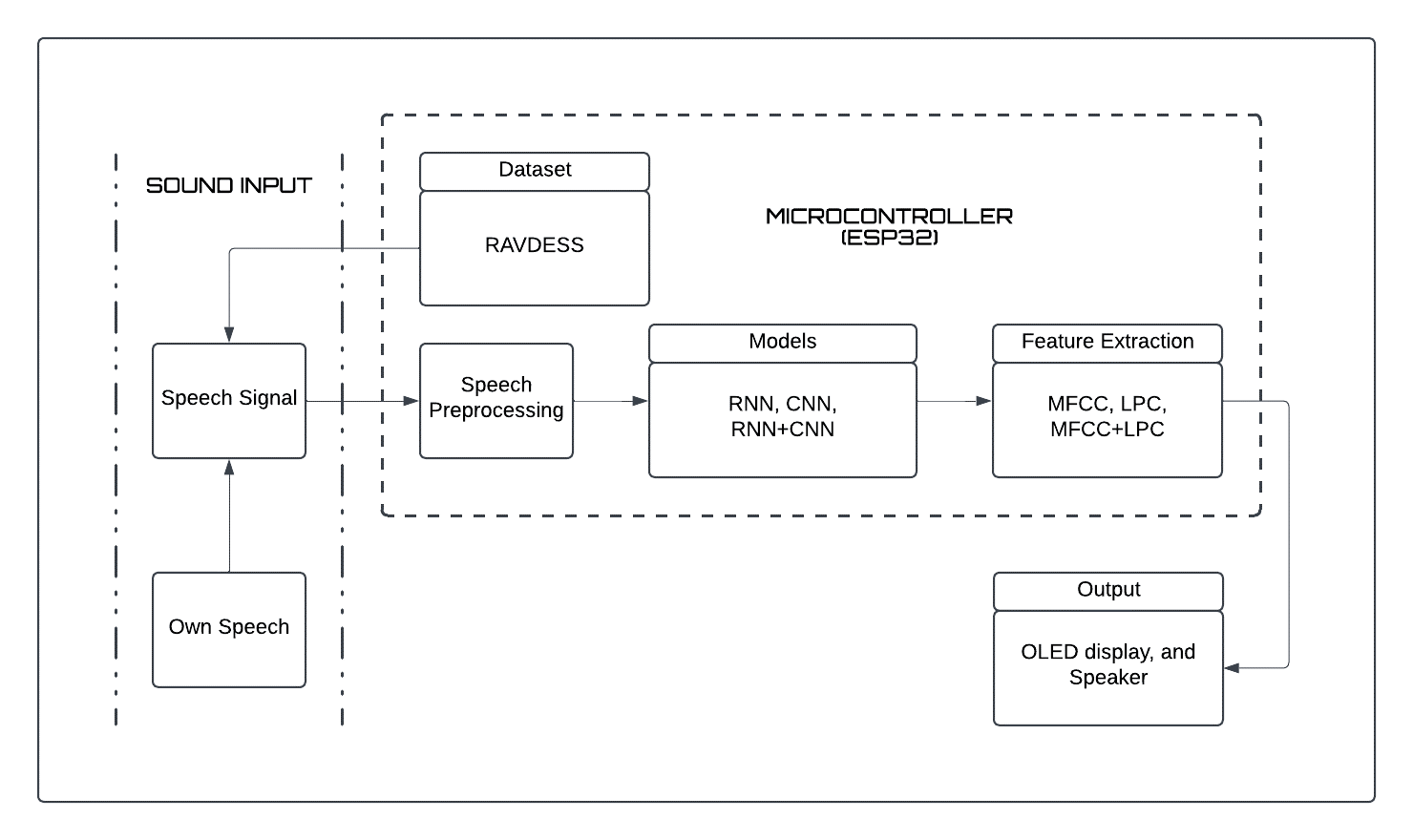
Speech emotion recognition (SER) is another major area of affective computing where machines are also capable of detecting and responding to human emotions real time. Nevertheless, it has been found that implementing deep learning-based SER systems on low-power microcontrollers is still a challenge because of computation and memory constraints, and inference time. The research paper describes the design and implementation of an AI-based SER system to provide human-machine interaction (HMI) with the help of an ESP32 microcontroller, an INMP441 digital MEMS microphone, and a MAX98357A audio output module. Preprocessing of speech signals was done by resampling, normalization, and trimming of silences and, features were extracted with Mel-Frequency Cepstral Coefficients (MFCC), Linear Predictive Coding (LPC), and a combined MFCC+LPC representation. The RAVDESS dataset was trained and tested using Convolutional Recurrent Neural Networks (CRNN), Convolutional Neural Networks (CNN), and Recurrent Neural Networks (RNN). The experimental results showed that the CNN model with hybrid MFCC + LPC features had the most favorable performance with an accuracy of 92.01%, precision of 92.11%, recall of 92.52%, and F1-score of 92.03% relative to the RNN and CRNN architecture. The system was shown to be able to perform stable real-time inference at a latency of less than 400 ms, confirming its applicability to embedded applications. These results establish the practicability of successful implementation of high-performing SER systems on the resource-constrained platforms, and present applications in assistive robotics, healthcare, education, and emotion-sensitive IoT devices